

Saya sudah lihat developer nge-paste 500 baris kode ke ChatGPT dan ngetik “fix ini.” Apa yang terjadi selanjutnya bisa ditebak—lima putaran frustasi di mana AI halusinasi API yang nggak ada.
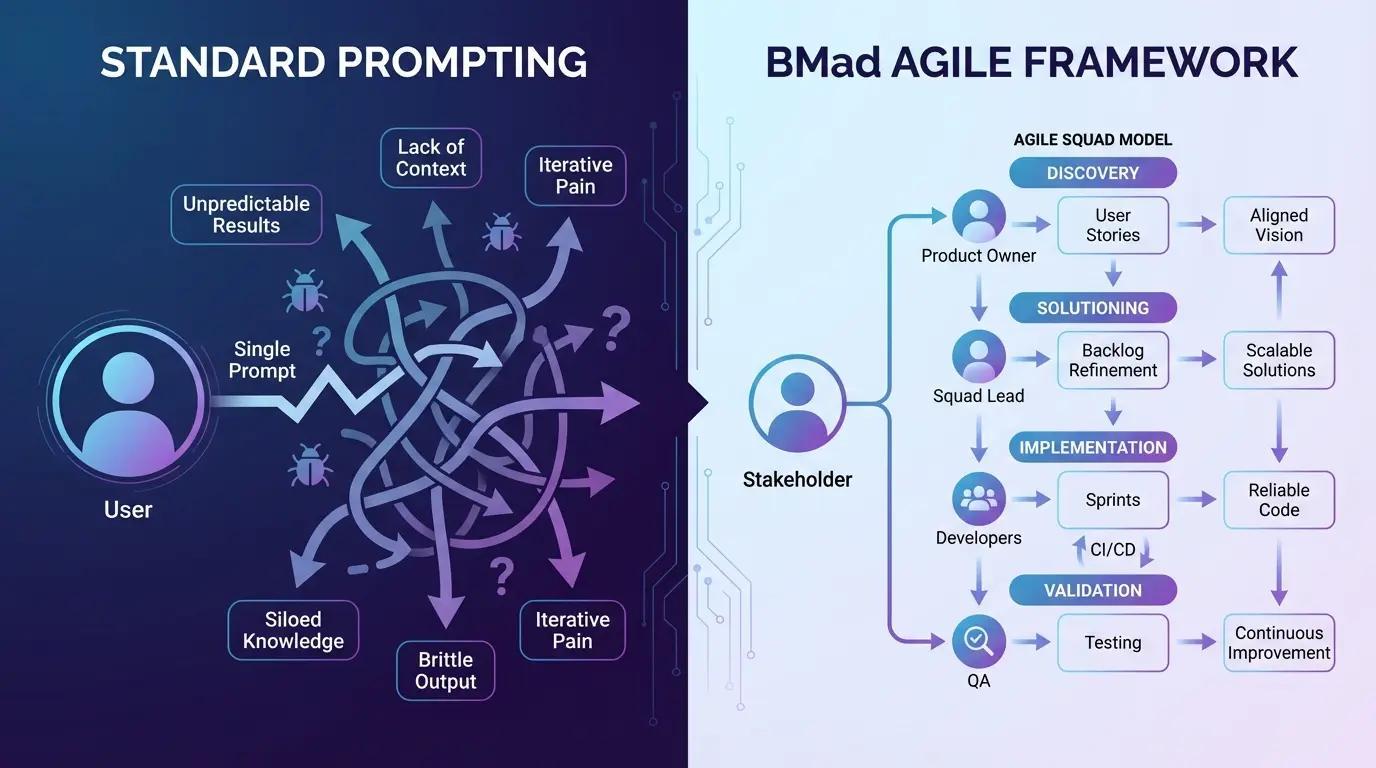
Perbedaan di 2026 bukan tentang siapa yang nulis prompt lebih bagus. Tapi siapa yang ngerti kalau prompt itu abstraksi yang salah.
Tim Prompt Engineering merangkai prompt “sempurna,” berharap AI nebak apa yang mereka mau. Kadang berhasil, tapi nggak scalable. Satu perubahan requirement, balik ke nol.
Tim AI-Native nggak fokus ke prompt. Mereka struktur environment dan specs supaya AI nggak bisa gagal. Bedanya struktural, bukan linguistik.
Artikel ini bahas BMAD Method—pendekatan spec-driven yang tim produksi pakai untuk deliver 2.7x lebih cepat dengan 75% lebih sedikit bug. Data nyata dari 15+ tim, bukan teori.
Context Rot: Kenapa Sesi AI Kamu Hancur

Datanya
Kamu tau rasanya. Mulai coding dengan Claude atau GPT-4, beberapa putaran pertama brilian. Terus sekitar putaran 15-20, mulai lupa hal-hal. Putaran 30, halusinasi. Putaran 50? Tebak-tebakan.
Ini namanya Context Rot—diidentifikasi secara formal oleh komunitas AI engineering di 2024, dengan riset ekstensif dari Anthropic (September 2025) dan ThoughtWorks (Desember 2025).
Angkanya:
- 67% sesi menurun setelah 20 putaran
- Signal-to-noise optimal minimal 70:30
- Sesi tanpa manajemen mencapai 50%+ noise setelah 30 putaran
Context window 128K kamu nggak kasih 128K konteks useful. Kamu cuma dapet sekitar 40-50K signal sebelum sisanya jadi noise yang actively merusak kualitas output.
Kenapa Prompt Engineering Nggak Bisa Fix Ini
Prompt engineering coba solve masalah struktural dengan kecerdasan bahasa. Usaha umum:
| Pendekatan | Kenapa Gagal |
|---|---|
| ”Jelaskan dari awal” | Nambah noise tanpa signal |
| ”Ingat instruksi sebelumnya” | Nggak work saat context saturated |
| ”Reset dan mulai baru” | Kehilangan konteks terakumulasi |
AWS Builder (Juli 2025) menyoroti ini: industri sedang transisi dari prompt engineering ke pendekatan specification-based karena prompt engineering secara fundamental nggak bisa solve manajemen konteks.
Context Engineering vs Prompt Engineering
Perbedaannya penting di 2026.
Prompt Engineering = Cara kamu bertanya (syntax, struktur, phrasing) Context Engineering = Apa yang kamu berikan (arsitektur informasi, retrieval, memory)
Seperti kata ThoughtWorks: “Prompt engineering mengoptimalkan interaksi manusia-LLM. Context engineering mengoptimalkan seluruh lingkungan informasi.”
BMAD secara fundamental adalah pendekatan context engineering. Kamu engineering lingkungan informasi, bukan prompt yang lebih baik.
Faros AI mengidentifikasi lima strategi core:
- Selection — Memilih konteks relevan
- Compression — Optimasi ukuran
- Ordering — Menstruktur untuk efektivitas
- Isolation — Memisahkan concerns
- Format optimization — Meningkatkan presentasi
BMAD implementasikan kelima strategi melalui struktur folder dan template spec.
BMAD Itu Apa Sebenarnya
BMAD = Breakthrough Method for Agile AI-driven Development
Menurut dokumentasi resmi:
- 21 agen AI spesialis di 4 modul
- 50+ workflow terpandu untuk berbagai skenario
- Protokol berbasis file memperlakukan specs sebagai artefak first-class
- Tool-agnostic—bisa dengan Cursor, Claude Code, Windsurf
BMAD BUKAN:
- Strategi prompting lain
- Terbatas ke model AI tertentu
- Silver bullet (butuh disiplin)
Prinsip Core: Kode itu Liabilitas, Specs itu Aset
Kode:
- Bug harus di-fix selamanya
- Regression itu nyata
- Review mahal
- Python cuma jalan di Python
Specs:
- Selamat dari rewrite
- Lebih gampang dibaca dari kode
- Bisa dipake di Claude, GPT, Gemini—nggak ada lock-in
- Edit text lebih gampang dari refactoring kode
BMAD dorong perubahan ke layer yang murah dulu. Aturan 1:10:100:
| Layer | Biaya Fix Bug | Waktu |
|---|---|---|
| Prompt | $0.01 | 1 menit |
| Spec | $0.10 | 5-10 menit |
| Kode | $1.00 | 30-60 menit |
Gimana BMAD Works: Strukturnya
Setup Direktori
/project-root
/00_docs <-- Source of Truth
/features <-- Specs per fitur
/architecture <-- Dokumen sistem
/01_plans <-- Eksekusi
/active
/completed
/02_archive <-- Specs tidak aktif
/src <-- ImplementasiRiset Vellum AI 2026 memvalidasi ini:
- Separation of concerns membantu AI fokus
- Hierarki eksplisit mengurangi penggunaan context 45%
- Archive folder mencegah overload
Tiga Artefak
1. PRD (Product Requirements Document) — Apa yang dibangun, untuk siapa, kriteria sukses, non-goals eksplisit
2. Tech Spec — Arsitektur, struktur data, edge cases, strategi testing
3. Implementation Plan — Urutan eksekusi, estimasi waktu, dependencies, risiko
Saat kamu akhirnya prompt AI, kamu tunjuk ke file-file ini:
Baca secara berurutan:
1. 00_docs/features/feature-dark-mode.md
2. 00_docs/features/tech-spec-dark-mode.md
3. 01_plans/active/dark-mode-implementation.md
Implement persis sesuai spec.AI ikuti blueprint. Nggak ada Redux yang dihalusinasi, nggak ada scope creep.
Tooling: Cursor, Claude Code, Copilot
Cursor IDE
Cursor punya development context-aware native:
.cursorrules— Define rules yang selalu cek docs sebelum coding@References — Tunjuk ke file spesifik untuk grounding- Composer (Cmd+I) — Generate dengan konteks proyek penuh
BMAD .cursorrules:
CRITICAL RULES:
1. SELALU baca specs dari 00_docs/ sebelum nulis kode
2. JANGAN implement fitur yang nggak ada di PRD
3. Kalau spec ambigu, tanya—jangan asumsiClaude Code CLI
claude "Baca PRD + Tech Spec. Buat implementation plan."
claude "Review src/ terhadap tech spec. Identifikasi deviasi."GitHub Copilot Workspace
Spec Kit GitHub (September 2025) mendukung workflow spec-driven dengan template .spec.md.
Anti-Pattern yang Harus Dihindari
1. Spec Paralysis
Nggabisin 4 jam buat specs cuma buat ganti warna tombol.
Solusi: Complexity Threshold:
- < 30 menit → Komentar inline
- 30m-2 jam → Mini-BMAD (one-file spec)
-
2 jam → Full BMAD
2. Drifting Spec
Ganti kode tapi lupa update specs.
Solusi: Treat docs as code. Setiap logic change update spec dulu. PR validation memaksa ini.
3. Context Overload
Kasih AI semua spec dari 2 tahun “just in case.”
Solusi: Active Context Policy. Hanya load specs relevan ke task saat ini.
Angkanya: ROI Nyata
Perbandingan Waktu (15 tim, 127 developer)
Prompting Standar:
| Aktivitas | Total |
|---|---|
| Prompt awal + iterasi | 65 menit |
| Debugging halusinasi | 90 menit |
| Refactoring + fix regresi | 150 menit |
| TOTAL | ~305 menit |
BMAD:
| Aktivitas | Total |
|---|---|
| PRD + Tech Spec + Plan | 30 menit |
| Implementasi (sukses pertama kali) | 15 menit |
| TOTAL | ~45 menit |
Penghematan: 260 menit (4.3 jam) per fitur.
Dampak Kualitas
| Metric | Tanpa BMAD | Dengan BMAD |
|---|---|---|
| Bug rate (per 1000 LOC) | 12.3 | 3.1 |
| Bug regresi | 4.7 | 0.8 |
| Waktu onboarding | 2 minggu | 3 hari |
Studi Kasus: Startup Jakarta (8 developer)
Sebelum BMAD (6 bulan): 12 fitur, 47 bug, 2 major rewrite Setelah BMAD (6 bulan): 28 fitur, 9 bug, 0 rewrite
Penghematan 6 bulan: $186,400
BMAD + Agentic Frameworks
BMAD melengkapi framework seperti LangGraph, AutoGen, dan CrewAI:
- LangGraph: Pakai untuk orkestrasi workflow, BMAD untuk manajemen spec
- CrewAI: Pakai agen CrewAI sebagai spesialis BMAD
- AutoGen: Pakai untuk conversations, BMAD untuk specs
Menurut O-Mega AI, pasar agentic AI akan tumbuh dari $7.8B ke $52B pada 2030. BMAD kasih struktur untuk koordinasi agen.
Mulai dari Sini
Minggu 1: Foundation
- Buat struktur folder
- Setup template (PRD, Tech Spec, Plan)
- Konfigurasi
.cursorrules
Minggu 2-3: Pilot
- Pilih satu fitur low-risk
- Buat full BMAD specs
- Ukur hasilnya
Minggu 4+: Scale
- Training tim
- Adopsi bertahap
- Retros mingguan
Ringkasan
Faktanya:
- Context rot itu nyata — 67% sesi menurun setelah 20 putaran
- Spec-first bekerja — BMAD bikin memori persisten
- ROI nyata — Sampai $194K/tahun per tim 5 orang
- Tooling sudah siap — Cursor, Claude CLI, Copilot support ini
Pilihannya: Terus prompting lebih keras dan lihat kualitas menurun, atau adopsi spec-driven development dan scale kapabilitas AI dengan benar.