


Bayangkan punya server GPU powerful yang bisa melayani jutaan request AI per hari, tapi Anda cuma bayar ketika server tersebut benar-benar bekerja. Bukan bayar bulanan, bukan bayar per jam penuh—tapi bayar per inference yang terjadi. Ini bukan mimpi. Ini adalah realitas serverless GPU di 2026.
Lanskap deployment model AI telah berubah secara fundamental. Kalau dulu organisasi harus sewa server GPU dedicated per bulan, sekarang ada cara yang jauh lebih efisien. Mari kita bahas tuntas.
Kenapa Serverless GPU Jadi Pilihan Utama di 2026
Pendekatan tradisional untuk infrastruktur AI—menyewa server GPU dedicated per bulan—sudah tidak masuk akal lagi bagi kebanyakan organisasi. Riset menunjukkan rata-rata utilisasi GPU hanya di kisaran 20-40%. Artinya? Perusahaan membayar infrastruktur yang menganggur 60-80% waktunya.
Platform serverless GPU mengatasi ketidakefisienan mendasar ini dengan model pay-per-inference. Model AI Anda otomatis scale dari nol saat idle hingga ribuan concurrent request saat permintaan melonjak, dan Anda hanya membayar waktu compute aktual. Dampak finansialnya signifikan—organisasi biasanya hemat 40-60% biaya GPU dibanding instance yang selalu aktif.
Timing-nya sangat relevan di 2026. Dengan rilisnya model open-source yang semakin powerful seperti Llama 4, DeepSeek R1, dan Qwen 3, semakin banyak organisasi yang mendeploy kemampuan AI sendiri daripada cuma mengandalkan layanan API. Model-model ini butuh resources komputasi yang serius, membuat keputusan infrastruktur jadi krusial baik untuk performa maupun profitabilitas.
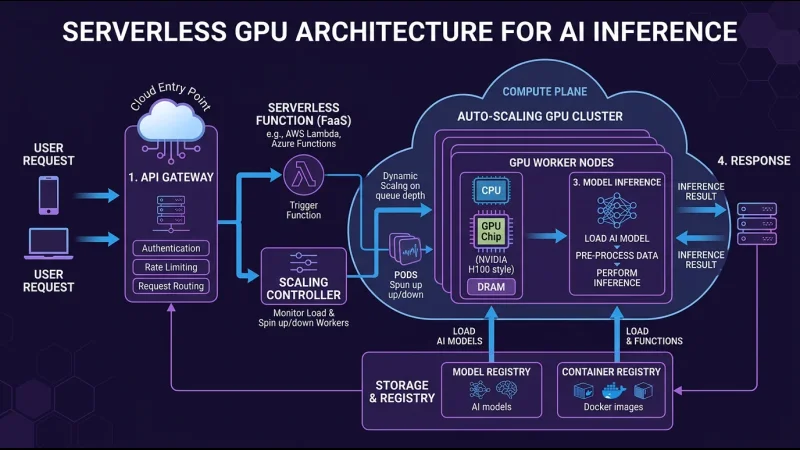
Memahami Lanskap Serverless GPU
Market serverless GPU sudah mature dengan beberapa platform yang menawarkan infrastruktur production-ready. Masing-masing punya karakteristik berbeda yang cocok untuk use case berbeda pula.
Koyeb: Pemimpin Performa-Harga
Koyeb sudah mapan sebagai platform serverless GPU terdepan, semakin diperkuat dengan akuisisi oleh Mistral AI—validasi jelas tentang pentingnya teknologi ini secara strategis. Platform ini menawarkan autoscaling native dan kemampuan scale-to-zero, memastikan Anda tidak pernah membayar untuk idle GPU time.
Harga Koyeb (2026):
- NVIDIA L40S: $1.55/jam
- NVIDIA A100: $2.00/jam
- NVIDIA H100: $3.30/jam
Yang membedakan Koyeb adalah dukungannya terhadap AI accelerator generasi berikutnya di luar GPU NVIDIA. Integrasi chip Tenstorrent memberikan akses ke hardware alternatif yang dioptimasi khusus untuk workload inference AI. Platform ini juga menawarkan availability global di berbagai region, memungkinkan deployment low-latency di seluruh dunia.
Modal: Development Python-First
Modal mengambil pendekatan code-first, menawarkan Python SDK yang mengabstraksi pengelolaan infrastruktur sepenuhnya. Ini sangat menarik bagi tim data science yang ingin fokus pada pengembangan model daripada kompleksitas deployment.
Harga Modal (2026):
- NVIDIA L40S: $1.95/jam
- NVIDIA A100: $2.50/jam
- NVIDIA H100: $3.95/jam
Trade-off dengan Modal adalah pendekatan SDK-centric. Semua harus didefinisikan dan di-deploy melalui framework Python mereka, yang bisa membatasi fleksibilitas kalau Anda migrasi aplikasi existing atau perlu menjalankan container image yang sudah jadi.
RunPod: Fleksibilitas dan Familiaritas
RunPod menawarkan opsi GPU serverless dan dedicated, memberikan jembatan bagi tim yang transit dari infrastruktur tradisional. Platform mereka support custom container, memudahkan migrasi workflow ML yang sudah ada.
Harga RunPod Flex (2026):
- NVIDIA L40S: $1.90/jam
- NVIDIA A100: $2.72/jam
- NVIDIA H100: $4.18/jam
RunPod unggul dalam kemudahan bagi pemula dengan environment preconfigured untuk framework ML umum. Namun, cold start bisa lebih lambat dibanding platform lain, dan biaya bisa meningkat untuk deployment production yang berjalan lama.
Cloudflare Workers AI: Inference Edge-Native
Cloudflare mengambil pendekatan yang berbeda dengan Workers AI. Alih-alih pricing per jam GPU, mereka menggunakan model billing unik berbasis “neuron” di $0.011 per seribu neuron. Ini bisa jauh lebih hemat untuk workload inference ringan.
Platform ini menjalankan inference di jaringan global Cloudflare yang mencakup 200+ kota, memungkinkan response AI dengan latency rendah untuk user di seluruh dunia. Dengan 50+ model tersedia termasuk Llama 4 Scout, DeepSeek R1, dan Qwen 3 Coder, katalognya mencakup kebanyakan use case umum.
Trade-off-nya adalah kontrol yang berkurang terhadap hardware spesifik. Anda tidak bisa memilih antara A100 atau H100 GPU—Cloudflare menangani abstraksi itu secara otomatis. Untuk banyak aplikasi, ini trade-off yang bisa diterima demi kemudahan dan manfaat distribusi global.
Perbandingan Harga: Memahami Opsinya

Memahami pricing antar platform butuh melihat di luar rate per jam. Pertimbangkan faktor-faktor ini:
Faktor Biaya Tersembunyi:
- Latensi cold start: Beberapa platform charge untuk waktu warm-up
- Biaya transfer data: Egress cost bisa menumpuk untuk generasi image/video
- Biaya storage: Model weights dan checkpoints butuh persistent storage
- Minimum request: Beberapa platform membulatkan ke minimum billing increment
Trade-off Biaya-Performa:
- GPU H100 3-4x lebih cepat dari A100 untuk inference model besar
- L40S menawarkan value terbaik untuk model ukuran menengah
- Pertimbangkan batch inference untuk memaksimalkan throughput per dollar
Untuk workload production tipikal yang berjalan 100 jam per bulan dengan GPU L40S:
- Koyeb: $155/bulan
- Modal: $195/bulan
- RunPod Flex: $190/bulan
Perbedaannya lebih terasa pada skala besar. Untuk workload enterprise yang berjalan 1000+ jam per bulan, memilih platform yang tepat bisa berarti penghematan ribuan dollar setiap bulan.
Strategi Optimasi Biaya yang Benar-Benar Ampuh
Kebanyakan organisasi overspend pada infrastruktur GPU sebesar 40-60%. Ini strategi yang terbukti untuk mengoptimalkan biaya inference AI Anda:
1. Workload Profiling dan Right-Sizing
Jangan default ke GPU paling powerful yang ada. Profile kebutuhan latency inference aktual Anda dan pilih tier GPU minimum yang memenuhi SLA. L40S sering bisa menangani workload yang tim unnecessarily provision H100 untuk.
2. Aktifkan Scale-to-Zero
Untuk aplikasi dengan pola traffic bervariasi, pastikan platform Anda benar-benar scale ke nol saat idle. Perubahan konfigurasi tunggal ini bisa mengurangi biaya 30-50% untuk banyak workload.
3. Batch Inference Request
Utilisasi GPU meningkat dramatis saat memproses request yang di-batch. Implementasikan request queuing dan batch processing untuk workload non-real-time seperti generasi embeddings atau klasifikasi bulk.
4. Teknik Optimasi Model
- Quantization: Kurangi presisi model dari FP16 ke INT8 atau INT4 dengan loss akurasi minimal
- Distillation: Gunakan student model kecil yang dilatih dari output teacher besar
- Pruning: Hilangkan model weights yang tidak perlu untuk mengurangi kebutuhan komputasi
5. Implementasikan Monitoring dan Budget
Setup dashboard monitoring biaya dan alert. Track metrics seperti:
- Biaya per request inference
- Persentase utilisasi GPU
- Efisiensi tokens/dollar
- Frekuensi cold start
6. Pertimbangkan Deployment Hybrid
Gunakan serverless GPU untuk traffic variable dan pertahankan baseline kapasitas dedicated untuk workload steady-state. Pendekatan hybrid ini mengoptimalkan baik biaya maupun latency.
Kapan Memilih Serverless vs. Dedicated GPU
Serverless GPU adalah pilihan tepat ketika:
- Traffic inference Anda spiky atau tidak terprediksi
- Anda menjalankan eksperimen atau prototype
- Anda ingin menghilangkan overhead DevOps
- Anda butuh distribusi global dengan latency minimal
- Model Anda fit dalam constraint platform
Dedicated GPU instance lebih masuk akal ketika:
- Anda punya traffic steady dan volume tinggi (reserved jadi lebih murah)
- Anda butuh konfigurasi hardware GPU spesifik
- Anda memerlukan kontrol maksimal atas environment inference
- Anda sedang training model bukan hanya inference
- Anda butuh guaranteed capacity saat peak period
Banyak deployment sukses menggunakan keduanya: dedicated GPU untuk kapasitas baseline dan serverless untuk spike traffic serta eksperimen model baru.
Memulai: Deployment Serverless GPU Pertama Anda
Memulai dengan serverless GPU sangat straightforward. Contoh deployment cepat menggunakan Cloudflare Workers AI:
// Inisialisasi AI binding di Worker Anda
const response = await env.AI.run(
"@cf/meta/llama-4-scout-17b-16e-instruct",
{
messages: [
{ role: "system", content: "Kamu asisten yang membantu" },
{ role: "user", content: "Jelaskan tentang serverless GPU computing" }
]
}
);Untuk deployment berbasis container di Koyeb:
# Deploy AI service yang sudah di-build
docker build -t my-ai-service .
docker push registry.koyeb.com/my-ai-service
koyeb service create my-ai-service --gpu l40sKuncinya adalah mulai dengan use case yang well-defined dan iterasi berdasarkan pola penggunaan aktual daripada proyeksi teoretis.
Masa Depan: Apa Selanjutnya untuk Infrastruktur AI Serverless
Market serverless GPU terus berevolusi dengan cepat. Trend kunci yang perlu diawasi:
- AI accelerator khusus: Di luar NVIDIA, platform menambahkan alternatif seperti Tenstorrent, Groq, dan custom chips
- Edge-native inference: Menjalankan model lebih dekat ke user dengan platform seperti Cloudflare Workers AI
- Platform AI terpadu: Menggabungkan training model, fine-tuning, dan inference dalam platform tunggal
- Routing cerdas: Secara otomatis memilih tipe GPU optimal berdasarkan kebutuhan model
- Computing carbon-aware: Menjadwalkan workload inference berdasarkan ketersediaan energi terbarukan
Kesimpulan
Platform serverless GPU telah mengubah fundamental ekonomi inference AI. Dengan menghilangkan biaya idle, menyediakan scalability instan, dan mengabstraksi kompleksitas infrastruktur, platform-platform ini memungkinkan organisasi dalam skala berapapun untuk mendeploy kemampuan AI yang canggih.
Kuncinya adalah mencocokkan requirement spesifik Anda dengan platform yang tepat. Koyeb menawarkan price-performance terbaik untuk workload umum. Cloudflare Workers AI unggul di deployment global dan edge-native. Modal memberikan developer experience terbaik untuk tim Python. RunPod menawarkan fleksibilitas untuk tim yang transit dari infrastruktur tradisional.
Saat model AI menjadi lebih capable dan accessible, keputusan infrastruktur yang Anda buat hari ini akan sangat mempengaruhi kemampuan Anda untuk iterate cepat, scale efisien, dan kontrol biaya. Serverless GPU bukan sekadar optimasi biaya—ini competitive advantage yang memungkinkan eksperimentasi dan deployment yang lebih cepat.
Langkah Selanjutnya
- Bandingkan pricing menggunakan pola workload aktual Anda
- Mulai dengan pilot project di platform pilihan Anda
- Implementasikan monitoring dari hari pertama
- Bergabung dengan Cloudflare Discord community untuk diskusi serverless AI
- Eksplorasi dokumentasi Koyeb untuk panduan deployment GPU
- Lihat katalog model Workers AI untuk model yang tersedia


